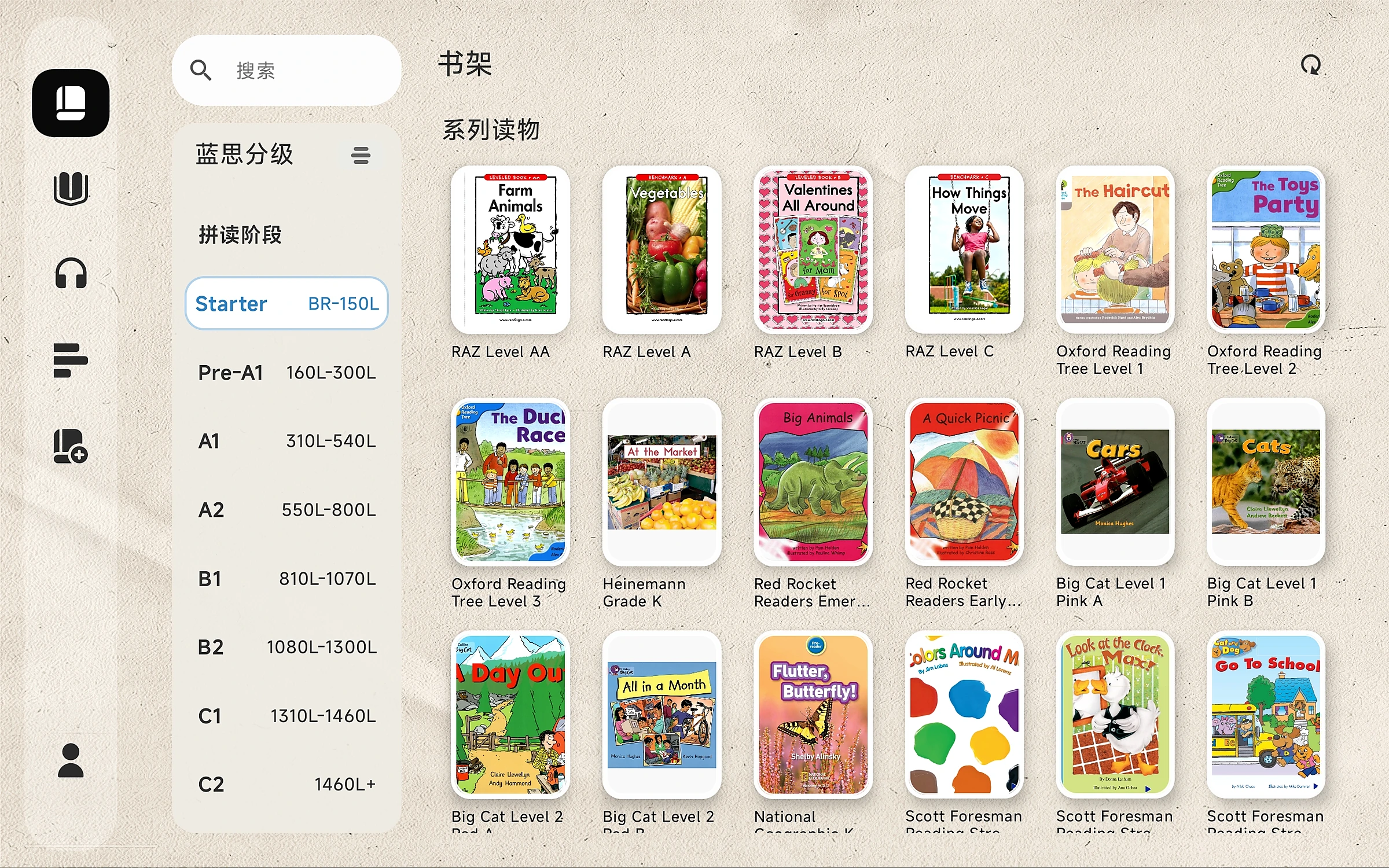
以阅读为核心
用优质读物承载词汇、语感和理解力,让学习从内容本身发生。
AI READING EDUCATION
StudyForce 学习原力,以分级阅读、智能伴学与语言训练,帮助学习者在真实阅读中建立理解力、表达力和长期学习信心。
学习原力不是把更多功能塞进屏幕,而是把阅读、理解、听读、表达和复习组织成清晰的学习闭环。 我们希望每一次打开 App,都能让学习者更靠近真实语言能力。
用优质读物承载词汇、语感和理解力,让学习从内容本身发生。
让 AI 在需要的时候出现,帮助查词、讲解、对话和反馈。
尊重学习节奏,用数据记录进步,用体验保护兴趣。
我们重视克制的产品设计、稳定的工程质量和对学习者的长期责任,每一次交付,都应该更清楚、更安全、更可持续。